![[Spring] 놀멍 서비스 개발 일지 - 로그 시스템 구축하기2](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcWxziw%2FbtsL7iT9f3v%2FFUgvzxhQTgaBoSSgjxHIf0%2Fimg.png)


이 글은 반려견 동반 가능 시설 공유 플랫폼 '놀멍'의 모니터링 서버를 구축하는 과정입니다.

놀멍 서비스 개발 일지 - 로그 시스템 구축하기1 이전 글에서 이어진 내용입니다.
로그 시스템 개발

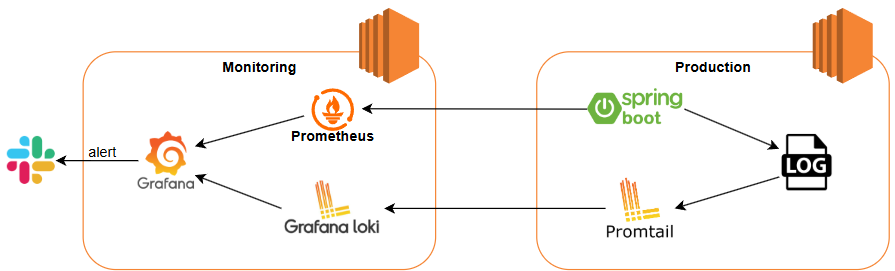
이전 글에서 설명한 대로 운영 서버와 모니터링 서버를 분리하여 관리하며, 각 서버의 아키텍처는 다음과 같습니다.
- 운영 서버: Spring Boot Application, Promtail
- 모니터링 서버: Prometheus, Loki, Grafana
1. docker-compose 설치
먼저, Docker Compose가 설치되어 있지 않다면 아래 명령어로 설치합니다.
놀멍 서버의 OS는 Amazon Linux2를 사용하고 있습니다. 만약, 다른 OS를 사용하신다면 Docker Compose 설치 명령어가 다릅니다.
sudo yum update -y
sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
2. 모니터링 서버 설정 설정
모니터링 서버에서는 Prometheus, Grafana, Loki를 실행합니다.
Promtail과 Loki의 버전은 동일하게 맞춰야 합니다!
docker-compose.yml 파일을 아래와 같이 설정합니다.
services:
prometheus:
image: prom/prometheus
container_name: prometheus
volumes:
- ./prometheus/config:/etc/prometheus
- prometheus-data:/prometheus
ports:
- "9090:9090"
command:
- '--storage.tsdb.path=/prometheus'
- '--config.file=/etc/prometheus/prometheus.yml'
restart: always
networks:
- t4y
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_PATHS_PROVISIONING=/etc/grafana/provisioning
- GF_AUTH_ANONYMOUS_ENABLED=true
- GF_SECURITY_ADMIN_PASSWORD=nolmung
restart: always
networks:
- t4y
loki:
image: grafana/loki:2.9.2
container_name: loki
ports:
- "3100:3100"
restart: always
networks:
- t4y
networks:
t4y:
driver: bridge
volumes:
prometheus-data:
3. 운영 서버 설정
운영 서버에서는 Spring Boot Application과 Promtail을 실행하며, Promtail이 Loki로 로그를 전송합니다.
#version: '3.8'
services:
springboot-app:
container_name: springboot-app
image: hyewonbae/nolmung
ports:
- "443:8080"
volumes:
- /home/ec2-user/logs/info:/app/logs
restart: always
networks:
- t4y
promtail:
image: grafana/promtail:2.9.2
container_name: promtail
volumes:
- ./logs:/logs
- ./promtail-config.yml:/etc/promtail/config.yml
command:
- -config.file=/etc/promtail/config.yml
- -config.expand-env=true
restart: always
networks:
- t4y
networks:
t4y:
driver: bridge
logback-spring.xml에서 설정한 로그 파일 저장 경로를 volumes 설정과 일치시켜야 합니다.
저는 /home/ec2-user/logs/info와 /app/logs를 마운트하여 사용했습니다.
4. Promtail 설정
Promtail은 운영 서버의 로그를 Loki로 전송하는 역할을 합니다.
Promtail의 설정 파일 promtail-config.yml은 아래와 같습니다.
server:
http_listen_port: 9080
positions:
filename: /tmp/positions.yaml # 동기화 작업을 이루기 위해 promtail이 읽은 마지막 로그 정보를 저장하는 곳
clients:
- url: http://{모니터링 서버 uri}:3100/loki/api/v1/push # push할 Loki의 주소
scrape_configs:
- job_name: logging
static_configs:
- targets:
- localhost
labels:
job: logging
__path__: /logs/*.log
5. Loki 설정
Loki의 설정 파일 loki-config.yml은 아래와 같습니다.
auth_enabled: false
server:
http_listen_port: 3100
ingester:
lifecycler:
address: loki # 도커 컴포즈 파일에서 정의한 서비스 이름으로 수정
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 1h
max_chunk_age: 1h
chunk_target_size: 1048576
chunk_retain_period: 30s
max_transfer_retries: 0
schema_config:
configs:
- from: 2020-10-24
store: boltdb-shipper
object_store: filesystem
schema: v11
index:
prefix: index_
period: 24h
storage_config:
boltdb_shipper:
active_index_directory: /loki/boltdb-shipper-active
cache_location: /loki/boltdb-shipper-cache
cache_ttl: 24h
shared_store: filesystem
filesystem:
directory: /loki/chunks
compactor:
working_directory: /loki/boltdb-shipper-compactor
shared_store: filesystem
limits_config:
reject_old_samples: true
reject_old_samples_max_age: 168h
ingestion_burst_size_mb: 16
ingestion_rate_mb: 16
chunk_store_config:
max_look_back_period: 0s
table_manager:
retention_deletes_enabled: false
retention_period: 0s
ruler:
storage:
type: local
local:
directory: /loki/rules
rule_path: /loki/rules-temp
alertmanager_url: localhost
ring:
kvstore:
store: inmemory
enable_api: true
6. 컨테이너 실행
모든 설정이 완료되었으면, 각 서버에서 도커 컨테이너를 실행합니다.
docker-compose up -d
7. Grafana Data sources 설정
{모니터링 서버 uri}:3000 grafana 주소에 접속하여 Loki Data Source를 추가합니다.

URL 부분에는 {모니터링 서버 url}:3000을 입력합니다.
그리고 적절히 대시보드를 구성합니다.

Slack 연동을 통한 Error 알림 설정
모니터링 및 로깅 시스템을 구축하는 최종 목적은 시스템의 이상 징후를 파악하고, 이를 개발자에게 알림에 있습니다.
즉 , 데이터를 잘 수집하는 것만큼 중요한 것이, 적절한 시점에 개발자에게 알림을 보내고 있는지입니다.
개발자가 대시보드를 계속해서 모니터링할 수는 없으므로, ERROR 로그 발생 시 Slack으로 자동 알림이 전송되도록 설정하였습니다.

1. Slack Webhook URL 설정
Slack으로 알림을 보내기 위해서는 Slack Webhook URL이 필요합니다.
Webhook URL 설정 과정은 Slack Webhook URL 설정 를참고하시면 됩니다.
2. Grafana Contact points 설정
Slack과 연동하려면 Grafana Contact points를 설정해야 합니다.
이름과 Integration 유형을 선택하고, Webhook URL에 Slack API 홈페이지에서 생성한 Webhook URL을 입력합니다.

저희 팀은 10-error-alert 채널로 알림이 가게 설정하였습니다.

입력 후 오른쪽 상단에 Test 버튼을 눌러 정상적으로 알림이 오는지 확인합니다.
정상적으로 동작한다면, 아래와 같이 10-error-alert 채널로 TestAlert가 오는 것을 확인할 수 있습니다.

3. Alert rule 설정
이제 어떤 조건에서 Slack 알림을 보낼지 설정해야 합니다.

A파트 (ERROR 로그 감지 쿼리)
count_over_time({filename="/logs/info/err_application.log"} |= `ERROR` [1m])
위 쿼리는 1분 동안, err_application.log 파일에서 ERROR 키워드를 포함하는 로그 개수를 세고, B파트는 A파트의 결과가 1보다 크다면 알림을 전송합니다.

Pending period는 조건이 충족되더라도 알림을 즉시 보내지 않고, 일정 시간 동안 조건이 지속되는지 확인하는 대기 시간입니다.
예제 설정:
- Evaluated period: 10s
- Pending period: 20s
ERROR가 발생할 때마다 바로 알림을 보내면, 대규모 서비스에서는 알림이 쉴 새 없이 울릴 수 있습니다.
그래서 보통 Evaluated interval을 1분, Pending period를 5분으로 설정합니다.
알림 트리거 동작 방식
- 쿼리 조건(count_over_time({filename="/logs/info/err_application.log"} |= `ERROR` [1m]))이 충족되었는지 매 1분마다 확인
- ERROR 로그가 특정 임계값 이상 발생하면 이를 감지
- 5분 동안 ERROR 상태가 지속되면 Slack 알림 전송
- 중간에 ERROR 로그가 사라지면 카운트가 초기화
만약 이런 알림이 계속 온다면 Set evaluation behavior에 Configure no data and error handling 설정을 수정해야 합니다.
Alert state if no data or all values are null을 No Data로 설정하면, 데이터가 없을 때도 알림이 발생합니다.

이러한 Alert를 발생시키지 않으려면 No Data에서 OK로 설정을 변경하면 됩니다.

마지막으로, Contact points에 만들어준 grafana-slack을 연결하고 summary를 작성합니다.
3. Notification policies 설정

저희 팀은 위 값들을 모두 1s로 설정했습니다. 그 이유는 서비스 운영 초기에는 QA와 UT로 발견하지 못한 에러가 많을 것이라 판단하였고, 사용자도 엄청 많지 않아 ERROR 로그가 발생한 그 즉시 장애를 해결할 수 있다고 판단했습니다.
Group wait
- 알림이 처음 생성된 후 대기하는 시간
- 동일한 그룹에 속하는 추가 알림들을 기다렸다가 한 번에 묶어서 전송
- 너무 짧으면 개별 알림이 많이 발생하고, 너무 길면 긴급한 알림이 지연될 수 있음
Group interval
- 같은 알림 그룹에서 새로운 알림을 묶어 보낼 간격
- Group wait 이후에 새로운 알림들이 그룹에 추가될 때 이 간격으로 알림을 계속 보냄
Repeat interval
- 동일한 알림 그룹에 대해 반복적으로 알림을 보낼 간격
- 경고가 해결되지 않고 계속 유지될 경우, 알림이 반복해서 전송됨
- 너무 짧으면 불필요한 노이즈가 발생하고, 너무 길면 지속적인 문제가 간과될 수 있음
4. 결과

모니터링을 통한 신속한 장애 대응
서비스 배포 후, Slack Alert를 통해 다음과 같은 에러 알림이 발생했습니다.

이때가 밤 9시였지만, 미리 구축한 모니터링 시스템 덕분에 신속하게 장애 상황을 인지할 수 있었습니다.
알림을 받은 즉시 팀원들과 협업하여 원인을 분석하고, 단 18분 만에 장애를 해결할 수 있었습니다.

참고자료
Grafana, Loki, Promtail 을 이용한 로그 모니터링 및 알림 시스템
로그 모니터링 시스템의 필요성 Logback을 이용해 날짜별, 로그 레벨별 로그 파일들을 관리하고 있었지만, 로그를 확인하려면 개발, 운영 서버에 직접 들어가서 log 파일을 열어서 확인해야 했습니
creampuffy.tistory.com
[Grafana] Grafana NoData Alert 이슈 해결
개요 Grafana 에서 Loki 로 수집된 로그 정보를 LogQL 로 조회를 시도하려던 중, 그라파나에서는 수집된 데이터가 없으면 return 값을 NoData 로 반환해 줍니다. LogQL 을 이용하여, Grafana Alert 를 생성하는
afsdzvcx123.tistory.com
불편했던 로그 시스템 전환기 with PLG
이번글에서는 Observability 도구로써 PortfoGram에 Loki,Promtail, Grafana를 사용한 경험에 대해 이야기해보겠습니다.
medium.com
'Spring' 카테고리의 다른 글
| [Spring] 놀멍 서비스 개발 일지 - 로그 시스템 구축하기1 (3) | 2025.01.25 |
|---|---|
| [Spring] 놀멍 서비스 개발 일지 - 지도 화면 개발하기2(공간 인덱스 적용) (0) | 2025.01.07 |
| [Spring] 놀멍 서비스 개발 일지 - 지도 화면 개발하기1 (0) | 2025.01.05 |
| [Spring] Redis 테스트 환경 구축하기(Embedded Redis) (2) | 2024.12.31 |
| [Spring] URL 이미지 리사이징 후, S3에 업로드 (3) | 2024.07.28 |
느리더라도 단단하게 성장하고자 합니다!
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Spring] 놀멍 서비스 개발 일지 - 로그 시스템 구축하기1](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FAx4QS%2FbtsL1svBegQ%2Fyx6yGFzsuOkbVa0WScgn4K%2Fimg.png)
![[Spring] 놀멍 서비스 개발 일지 - 지도 화면 개발하기2(공간 인덱스 적용)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FpUEC2%2FbtsLEYP05zm%2FpvfNw2gPZJ05KAotXOSOQK%2Fimg.jpg)
![[Spring] 놀멍 서비스 개발 일지 - 지도 화면 개발하기1](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdXxNmO%2FbtsLFdZy87W%2Fy1kIh9w85MfAG9Ilqu4bYk%2Fimg.jpg)
![[Spring] Redis 테스트 환경 구축하기(Embedded Redis)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdVum8F%2FbtsLCFvrnea%2Fv6IzHV7DU5z7V8chqyUWHK%2Fimg.png)