![[컴퓨터 구조] 캐시 메모리 파헤치기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbOSnvZ%2FbtsLLOZHWcP%2FAAAAAAAAAAAAAAAAAAAAAG0VHvxj_adyKF7rV_uss0xlbCK1qe0ZvErGDvR9f5-c%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DbMrn%252FBsrdtEBpnqvXxLXL0vI99Y%253D)

캐시 메모리
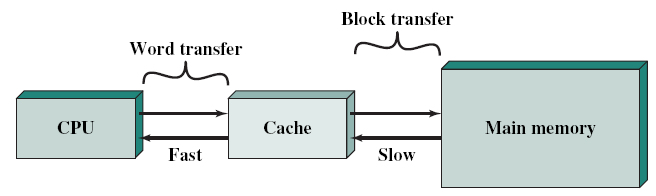
CPU가 프로그램을 실행하는 과정에서 메인 메모리에 접근하는 것은 시간이 오래 걸립니다.
CPU가 레지스터에 접근하는 속도보다 느리기 때문에, 아무리 빠른 연산속도를 가진 CPU라도 메모리에 접근하는 속도가 느리면 그 효율이 떨어질 수 있습니다. 이러한 문제를 해결하기 위해 탄생한 저장장치가 캐시 메모리입니다.
캐시 메모리는 CPU와 메인 메모리 사이에 위치한 SRAM 기반의 저장장치입니다.
캐시 메모리는 CPU가 사용할 일부 데이터를 미리 메모리에서 가져와 저장합니다. 이 덕분에 CPU는 메인 메모리까지 갈 필요 없이 캐시 메모리에 저장된 데이터를 활용할 수 있습니다.

캐시 메모리는 코어와 가까운 순으로 L1, L2, L3 캐시로 나뉩니다.
L1과 L2 캐시는 일반적으로 코어 내부에 위치하고, L3 캐시는 코어 외부에 위치합니다.
위 그림처럼 코어가 2개인 멀티코어 프로세서의 경우 L1 및 L2 캐시는 각 코어마다 고유한 캐시 메모리로 할당되고, L3 캐시는 두 개의 코어가 공유하는 형태로 구현됩니다.

캐시 히트와 캐시 미스
앞서 설명한 것처럼 캐시 메모리는 메모리로부터 일부 데이터를 가져와 저장합니다.
CPU가 사용할 것 같은 데이터를 미리 가져와 저장해둡니다.
이때, 캐시 메모리가 예측하여 저장한 데이터가 CPU에 의해 실제로 사용되는 경우를 캐시 히트(cache hit)라고 하며, 반대로 자주 사용될 것으로 예측해 저장했지만 틀린 예측으로 인해 CPU가 메모리로부터 필요한 데이터를 직접 가져와야 하는 경우를 캐시 미스(cache miss)라고 합니다.
캐시가 히트되는 비율을 캐시 적중률(cache hit ratio)이라고 하며, 범용적으로 사용되는 컴퓨터의 캐시 적중률은 85~95% 이상입니다.
캐시 적중률 = 캐시 히트 횟수 / (캐시 히트 횟수 + 캐시 미스 횟수)
캐시 메모리는 CPU가 사용할 법한 데이터를 어떻게 예측하는가?
캐시 메모리는 참조 지역성의 원리(Locality of reference)라는 특정한 원칙에 따라 메모리로부터 가져올 데이터를 결정합니다. 참조 지역성은 주로 두 가지 유형으로 나뉩니다.
- 시간 지역성(Temporal Locality)
- 공간 지역성(Spatial Locality)

1. 시간 지역성(Temporal Locality)
시간 지역성은 CPU가 최근에 접근했던 메모리 공간에 다시 접근하려는 경향을 의미합니다.
대표적인 예시는 변수입니다. 프로그램이 실행되는 동안 변수는 여러 번 사용되며, 반복문(for, while)에서도 특정 메모리 값을 반복적으로 접근하게 됩니다. 이처럼 방금 전에 접근했던 메모리를 다시 참고하게 될 확률이 높아지는 것이 시간 지역성입니다.
2. 공간 지역성(Spatial Locality)
공간 지역성은 CPU가 접근한 메모리 공간의 근처에 있는 데이터에 접근하려는 경향을 의미합니다.
대표적인 예시는 배열과 같은 연속적인 데이터 구조에 순차적으로 접근하는 경우입니다.
다음은 두 가지 접근 방식의 코드입니다.
캐시 친화적 코드
public static void main(String[] args) {
int[][] matrix = new int[20000][20000];
for (int i = 0; i < 20000; i++) {
for (int j = 0; j < 20000; j++) {
matrix[i][j] = 1;
}
}
}반 캐시 친화적 코드
public static void main(String[] args) {
int[][] matrix = new int[20000][20000];
for (int i = 0; i < 20000; i++) {
for (int j = 0; j < 20000; j++) {
matrix[j][i] = 1;
}
}
}
위 첫 번째 코드와 두 번째 코드의 메모리 접근 방식은 공간 지역성 측면에서 차이가 있으며, 이로 인해 실행 속도에 큰 차이가 발생합니다.
위 두 코드의 실행결과는 각각 아래와 같습니다.


캐시 메모리의 쓰기 정책
현재 메모리의 a번지에 100이라는 값이 저장되어 있고, 이 값을 캐시 메모리에도 저장되어 있다고 가정해 보겠습니다.
CPU가 이 값에 접근할 때는 캐시 메모리에 통해 값을 읽어옵니다.
이제 CPU가 이 값을 100에서 200으로 변경하고 싶으면 어떻게 해야할까요?
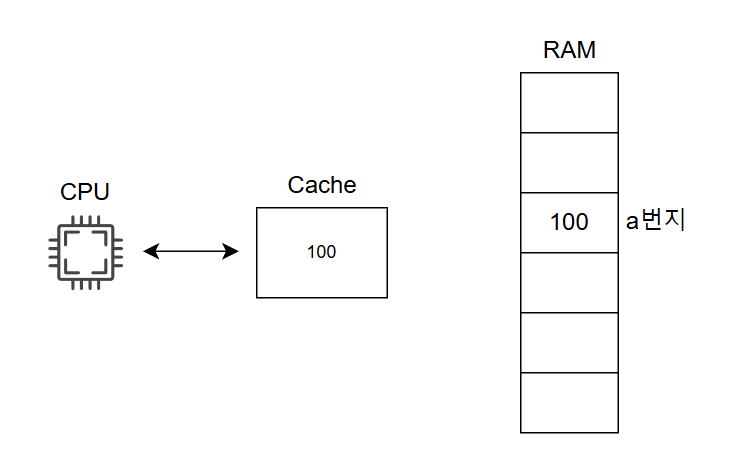
메모리 a번지에 있는 값을 바로 변경한다고 가정해봅시다.
명령어1: a번지 값을 200으로 변경하기 // 메모리 값은 변경되었지만 캐시 메모리 내의 값은 그대로 100이다.
명령어2: a번지 값 출력하기 // 캐시 메모리를 읽어 들일 경우 여전히 100을 출력
이처럼 메모리와 캐시 간의 불일치로 인해 일관성이 깨지는 문제가 발생합니다.
이를 방지하기 위한 대안에는 크게 두 가지가 있습니다.
- 즉시 쓰기(write-through): 캐시 메모리와 메모리에 동시에 데이터를 쓰는 방식입니다. 메모리를 항상 최신 상태로 유지하여 캐시 메모리와 메모리 간의 일관성이 깨지는 상황을 방지합니다. 그러나 데이터를 쓸 때마다 메모리를 참조해야 하므로 버스의 사용 시간과 쓰기 시간이 늘어나는 단점이 있습니다. 결국, 메모리 접근을 최소화하기 위해 캐시 메모리를 만들었는데, 데이터를 쓸 때마다 메모리에 접근해야 한다면 캐시 메모리의 효율성이 떨어지게 됩니다.
- 지연 쓰기(write-back): 캐시 메모리에만 값을 저장하고, 수정된 데이터를 추후 한 번에 메모리에 반영하는 방식입니다. 메모리 접근 횟수를 줄일 수 있어 즉시 쓰기 방식에 비해 속도는 빠르지만, 일관성이 깨질 수 있습니다.
이 외에도 다른 코어가 사용하는 L3 캐시 메모리와의 불일치도 발생할 수 있습니다.
참고
강민철. 『 이것이 취업을 위한 컴퓨터 과학이다 』
[컴퓨터 구조] Memory
컴퓨터의 역사에 관한 레포트를 쓰기 위해 학교 도서관에 왔다고 가정해봅니다.많은 책들을 뽑아 책상에 앉아 자료 조사를 하는 도중, 컴퓨터에 대한 많은 내용을 찾았지만, 그 중 EDSAC에 대한
velog.io
캐시 메모리 (캐시 일관성, 캐시의 쓰기 정책)
캐시 메모리 (Cache Memory) 탄생 배경현대 컴퓨터의 주기억장치 메모리는 대부분 100% SDRAM으로 구성되며 SDRAM은 보조 기억장치에 비해 빠르긴 하지만 한 번 메모리에 접근할 때마다 지연시간(Latency)
shuu.tistory.com
'컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 메인 메모리(RAM) 파헤치기 (0) | 2025.01.11 |
|---|---|
| [컴퓨터 구조] CPU 파헤치기 (1) | 2025.01.10 |
느리더라도 단단하게 성장하고자 합니다!
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[컴퓨터 구조] 메인 메모리(RAM) 파헤치기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fdu2dSy%2FbtsLKFPP47O%2FAAAAAAAAAAAAAAAAAAAAAGUsyMVqmoNs8CHTrtmCpt2iy4I5dW7d6k0xQRnarqmc%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3D%252B8i0OAvZWZ6b6ewSeQDN2o7p2kk%253D)
![[컴퓨터 구조] CPU 파헤치기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fv3ynt%2FbtsLHNuEDYf%2FAAAAAAAAAAAAAAAAAAAAAItbcaeVCyZPwXOc1w5g25CAhwH8Gm17y3f-ImngkiVJ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3Dgk5x7SnW8NBZHysuwObUf9Y0bZ0%253D)