

우리의 데이터는 실제로 보조기억장치(하드디스크, SSD, USB 등)에 저장됩니다.

하드디스크는 원형의 플레이트로 구성되어 있습니다. 플레이트는 트랙으로 나뉘며, 트랙은 다시 몇 개의 섹터로 나뉩니다.
원형의 플레이트는 매우 빠른 속도로 회전하고, 회전하는 플레이트에 하드디스크의 암과 헤드가 접근하여 원하는 섹터에서 데이터를 가져옵니다. 하드디스크에 저장된 데이터를 읽어오는 데 걸리는 시간을 액세스 시간(access time)이라 합니다. 액세스 시간은 데이터의 저장 및 읽기에 많은 영향을 끼칩니다.
액세스 시간 = 탐색시간(액세스 헤드를 트랙에 이동시키는 시간) + 회전 지연시간(섹터가 액세스 헤드에 접근하는 시간) + 데이터 전송시간(데이터를 주기억장치로 읽어오는 시간)
이러한 액세스 시간으로 인해, DBMS가 하드디스크에 데이터를 저장하고 읽어올 때, 속도 문제가 발생할 수밖에 없습니다.
컴퓨터가 연산하는 속도는 빠르지만, 디스크의 액세스 속도는 상대적으로 느리기 때문입니다. 디스크 액세스 속도는 주기억장치보다 100배 이상 느립니다.
이러한 속도 문제를 줄이기 위해 DBMS는 주기억장치의 일부를 버퍼 풀(Buffere Pool)로 사용합니다.
DB는 버퍼에 자주 사용하는 데이터를 저장하며, LRU 알고리즘을 이용하여 사용 빈도가 높은 데이터 위주로 저장하고 관리합니다.
LRU(Least Recently Used) 알고리즘: 기억장소를 관리하는 알고리즘으로, 가장 오랫동안 참조되지 않은 페이지를 교체하는 기법
인덱스
인덱스(index)란 데이터를 쉽고 빠르게 찾을 수 있도록 만든 데이터 구조입니다.
일반적인 RDBMS의 인덱스는 대부분 B-tree 구조로 되어 있습니다.

B-tree(Balanced-tree)는 데이터의 검색 시간을 단축하기 위한 자료구조입니다.
B-tree의 각 노드는 키 값과 포인터를 가집니다. 키 값은 오름차순으로 저장되어 있으며, 키 값 좌우에 있는 포인터는 각각 키 값보다 작은 값과 큰 값을 가진 다음 노드를 가리킵니다
리프 노드에는 해당 데이터의 저장 위치에 대응하는 rowid가 있어 찾고자 하는 행을 바로 찾을 수 있습니다.
B-tree는 100만 개의 튜플을 가진 데이터도 디스크 블록을 서너 번 읽으면 찾을 수 있습니다.
하지만 데이터의 변경이나 추가가 잦을 경우 B-tree의 모양을 유지하기 위해 노드의 분할 및 이동이 자주 발생한다는 문제가 있습니다.
인덱스의 특징
- 인덱스는 테이블에서 한 개 이상의 속성을 이용하여 생성
- 빠른 검색과 함께 효율적인 레코드 접근 가능
- 순서대로 정렬된 속성과 데이터의 위치만 보유하므로 테이블보다 작은 공간을 차지
- 저장된 값들은 테이블의 부분집합
- 일반적으로 B-tree 형태의 구조를 가짐
- 데이터에서 수정, 삭제 등의 변경이 발생하면 인덱스를 재구성해야 함
클러스터 인덱스(Clustered Index)
클러스터 인덱스는 인덱스의 리프 노드들이 정렬된 상태로 저장된 테이블 자체가 됩니다.
클러스터 인덱스를 구성하기 위해 행 데이터를 해당 열(보통 PK)로 정렬한 후, 루트 페이지를 생성합니다.
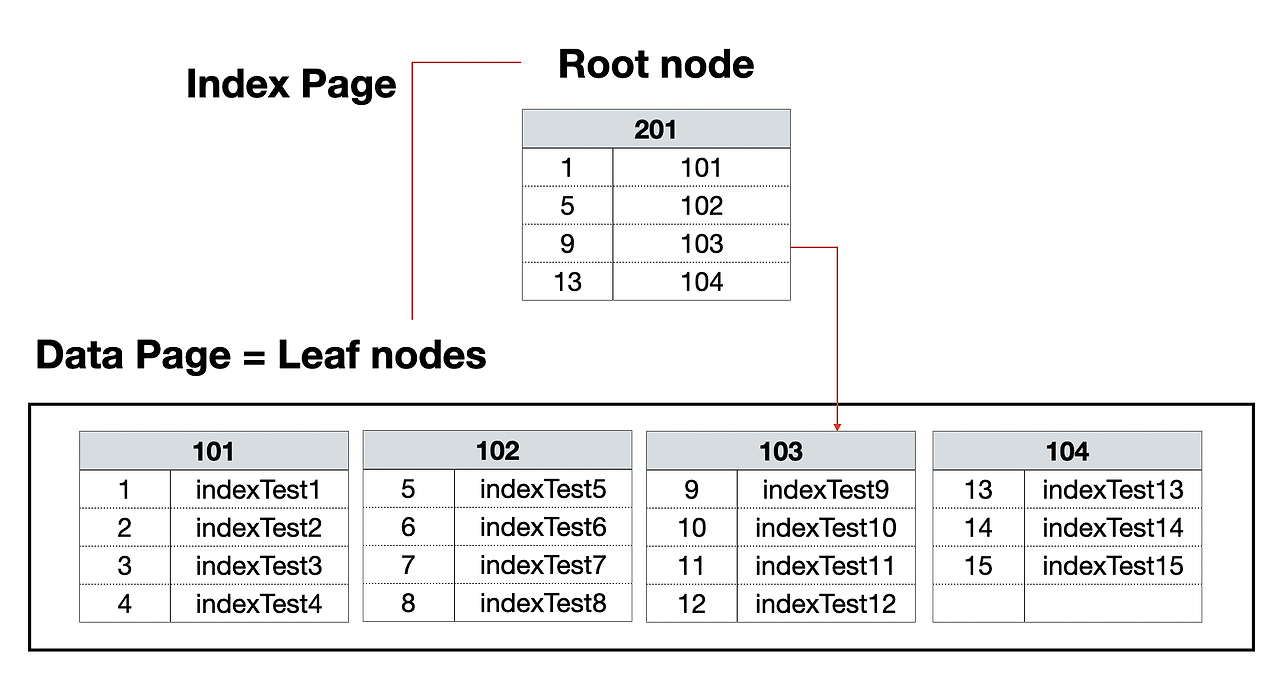
클러스터 인덱스 키 값을 기준으로 데이터가 정렬되어 있어 특정 값을 쉽게 찾을 수 있으며, 범위로 검색한다고 해도 이미 정렬되어 있으므로 효율적입니다.
클러스터 인덱스 특징
- 테이블당 하나의 클러스터 인덱스만 생성 가능
- 클러스터 인덱스는 테이블 생성 시 기본키를 생성하면 자동으로 생성됨
- 데이터 삽입, 수정, 삭제 시 항상 정렬 상태 유지
- 물리적으로 행을 재배열
- 물리적으로 정렬되어 있어 검색 속도가 보조 인덱스보다 빠름(삽입, 수정, 삭제는 느림)
데이터 검색 순서: 루트 페이지 ⮕ 리프 페이지
보조 인덱스(Secondary Index) 또는 넌 클러스터 인덱스(Non-Clustered Index)
보조 인덱스는 데이터 페이지를 건들지 않고, 별도의 장소에 인덱스 페이지를 생성합니다.
인덱스 페이지의 리프 노드에는 실제 데이터 값이 아닌 테이블상의 데이터 위치를 지정하는 rowid를 저장합니다.
rowid를 저장하기에 테이블의 자료가 무작위로 저장되어 있어도 쉽게 찾을 수 있습니다.
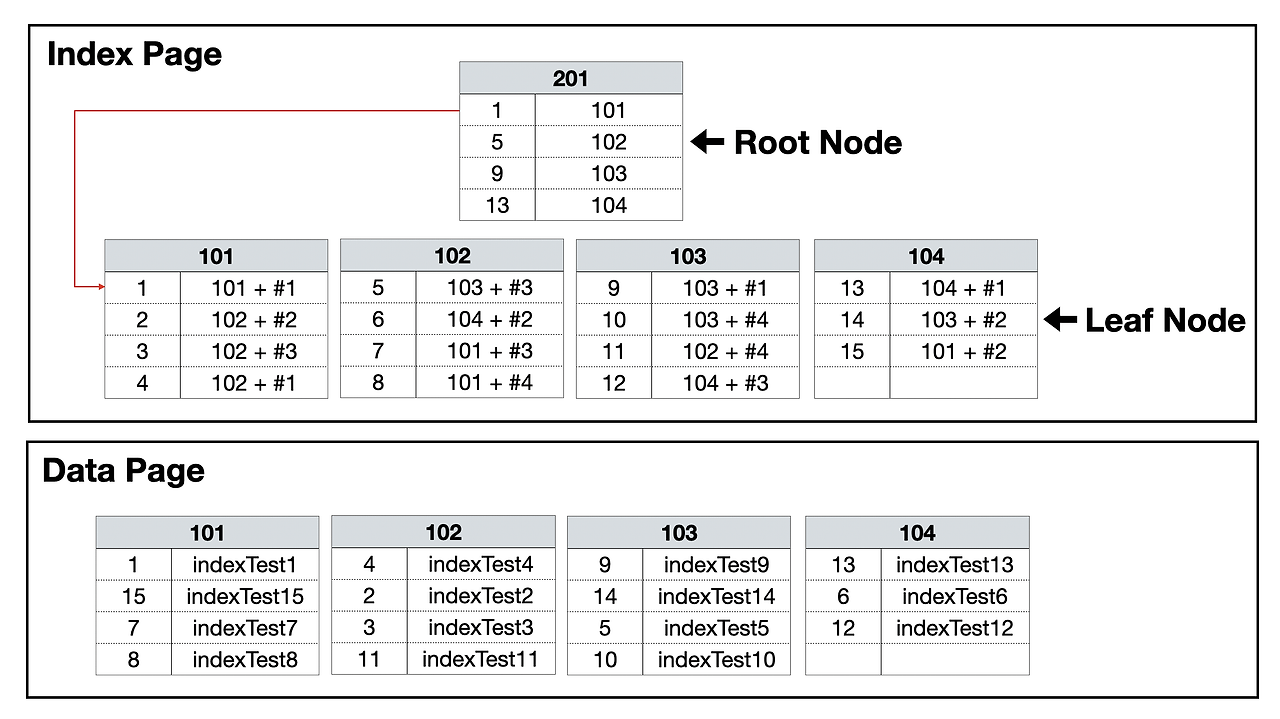
보조 인덱스 특징
- 테이블당 여러 개의 보조 인덱스 생성 가능
- 여러 개의 컬럼을 복합적으로 결합하여 사용하는 인덱스 생성 가능
- 범위 검색은 데이터가 저장된 블록 값들의 저장 순서가 일정하지 않을 수 있어 원하는 만큼의 빠른 검색 효과를 보장할 수 없음
- 인덱스 조회 시 비용이 많이 발생 (거쳐야 하는 단계가 클러스터 인덱스보다 많다)
인덱스를 무조건 사용해야할까?
인덱스를 사용하는 이유는 데이터를 빠르게 검색하기 위해서입니다.
그러나 인덱스를 생성한다고 해서 무조건 검색 속도가 빨라지는 것은 아닙니다.
데이터 양이 매우 적거나 데이터 값의 종류가 몇 가지 안 되어 선택도가 높을 경우, 인덱스를 사용하지 않고 검색하는 편이 더 빠를 수 있습니다.
선택도(Selectivity): 1 / 서로 다른 값의 개수
예를 들어, 직원 테이블에 100개의 행이 있는데 남성이 100명이라면 중복도가 높아 인덱스를 사용하는 것이 부적합할 수 있습니다. 마찬가지로, 대한민국에 거주하는 사람 중 한국인을 찾는 경우에도 풀 스캔이 더 빠를 수 있습니다.
즉, 중복된 값이 많을수록 선택도가 높아져 인덱스를 사용하기 부적합합니다.
인덱스 생성 전 고려사항
- Where 절이나 Join에 자주 사용되는 속성을 사용
- 단일 테이블에 인덱스가 많으면 속도가 느려짐(테이블당 4~5개 권장)
- 속성의 선택도가 낮을 때 유리
추가적으로, 클러스터 인덱스와 보조 인덱스는 보통 함께 사용됩니다.
예를 들어, 고객이 도서관 홈페이지에서 야구에 대한 책을 찾을 때, '야구'라는 키워드를 입력하면 보조 인덱스를 이용하여 bookid를 찾고, 그다음에 bookid에 대한 클러스터 인덱스를 사용하여 도서를 찾습니다. 이렇게 하는 이유는 클러스터 인덱스로 저장된 데이터의 순서를 가능한 한 유지하면서 데이터의 삽입과 삭제에 대한 인덱스 관리 비용을 줄이기 위해서입니다.

인덱스 사용하기
1. 인덱스 생성
create index index_book on book(bookname);
2. 책이름으로 검색
select * from book where bookname = "야구를 부탁해"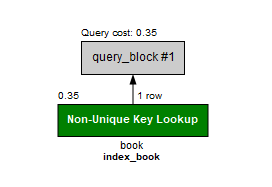
워크벤치의 Query -> Explain Current Statement를 통해 index_book을 이용해 데이터를 조회하는 것을 확인할 수 있습니다.
3. 인덱스 최적화
B-tree 인덱스는 데이터의 수정, 삭제, 삽입이 잦으면 노드의 갱신이 주기적으로 일어나 단편화 현상이 나타납니다.
이는 성능 저하로 이어지기 때문에 ANALYZE 문법을 사용해 인덱스를 다시 최적화해야 합니다.
단편화: 메모리 내의 빈 공간
analyze table book;
4. 인덱스 삭제
drop index ix_book on book;
참고자료
[도서] MySQL로 배우는 데이터베이스 개론과 실습(2판)
클러스터드 인덱스 (Clustered Index), 넌 클러스터드 인덱스 (Non Clustered Index)
인덱스는 데이터 레코드를 빠르게 접근하기 위해서 <키, 포인터>쌍으로 구성되는 데이터 구조이다.
velog.io
'Database' 카테고리의 다른 글
| [SQL] 기본키(PK)가 꼭 필요할까? (3) | 2024.07.12 |
|---|---|
| [MySQL] 외래 키(Foreign Key) 삭제하기 (1) | 2024.02.24 |
느리더라도 단단하게 성장하고자 합니다!
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[MySQL] 외래 키(Foreign Key) 삭제하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FblBEwt%2FbtsFjUEXYQI%2FAAAAAAAAAAAAAAAAAAAAAPEYlXWDkdPZDzDN4kEYg2Sz1I91L6HQ3HHpVxZaT4ai%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3Dv7rtA2ucQ%252F3EFWtXO7FTUZGYTgI%253D)